ҽ��AI�������������OpenAI HealthBench������δ����Ұ
��ҽ����Ƭ�ڶ�ĺ�����������˹����ܣ�AI������һ�����˵ĺ�����������������������������������ȷ�����Ҵ�����ʧƫ���������徲�ִ�����ı˰�������OpenAI�����Ƴ���HealthBench�������������Һ���������������Ϊҽ��AI������ָ��������ƫ�������
��ʵҽ��chang���������������IJ����Ի�
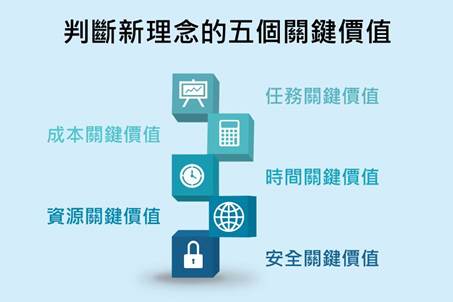
��������ҽ��AI��������ֽ��̸�������ȱ����ʵ��������HealthBench���ǰ�ҽ����chang������̨�������¼������ȫ��60������������262λִҵҽʦ�����5000�ζ���ҽ�ƶԻ���������Щ�Ի��������Ǽ��������רҵ��ͬ�����ҽ�����ݴ����ͷ��ȶ�Ԫchang���������������ҽʦ�뻼��֮�����ʵ��̸��������AI��ģ����ѧϰ�����������ٴ�����������
ҽʦ���ִ������ֳ߶���������AIЧ�����¶�
HealthBench����һ����������������ҽʦ������Ƶ�48,562������ϸ���������ȷ������������Ե���ͬ���������ѹ���������ⲻֻ��������ķ�����������ǽ�ҽ��רҵ��ϸ�����Ͻ�ע�����������������AI���������ˡ�ҽʦ���۹⡹�������������ٴ���ʵ�����
AI�Զ�����yuan���ǻ���רҵ�������Ž�
�����������������HealthBench�������µ�GPT-4.1��Ϊ�Զ�����yuan�������ƾ֤ҽʦ�ƶ��ij߶ȸ���ظ�����������ʵ��Ч����ʾ��AI������ҽʦ���ָ߶�һ�����������ȹ̿ɿ��������������AI�Լ���ĥ���Լ������������Լ���������������Ҳ��������߿�����Ч��������
��ս��ͻ�ƣ�AIҽ�Ƶ�����chang
HealthBench����������ѶȰ汾�������Hard������ս�������������ǿģ�ӵ÷ֽ�32%����Consensus������۽�ҽʦ�߶ȹ�ʶ�ĵ����徲�߶ȡ�������Ǹ�AI�����˲���Ŀ�chang�������Ͽ������������������Ҳ�л������徲�ſ�������������з�����ʶAI��ǿ�������������һ��ˢ���������
ǰ���ĽŲ����������16%�����60%�ķ�Ծ
��HealthBench�������OpenAI��ģ�Ӵ�GPT-3.5 Turbo��16%�������GPT-4o��32%��������ٵ�����o3ģ�����60%���ۺϵ÷��������չ����AIҽ�������Ŀ����������������������ܵ��������С��ģ��GPT-4.1 nano�Լ��ͳɱ�������Խ����ǰ��ǿʢ�汾����ζ��δ����Ч��ҽ��AI�������ռ������
�徲��ɿ��������AIҽ�Ƶıؾ�֮·
��Ȼ����ǿ��ģ�������������Ͽ���qing���µ÷�Ҳֻ��Լ40%��������������AI��ҽ���������в�С����ս�����HealthBench����������ǿ���AI��DZ���������Ҳ�������DZ������������������ȷ��ÿһ��ϣ�����������徲��ɿ��Ļ�����������
���Ź�������ȫ��ҽ��AI���ci���
HealthBench�����뷨ʽ������ȫ��Դ��Լ��ȫ��ҽ�ƻ���������ѧ�����빤ҵ����ϼ��룬�ƶ�ҽ��AI��ǰ����������ⲻ�������յ�ͻ�������������һchang���������ʢ�����������ҽ��AI����������ʵ���������츣����������
����������AI��ҽ�Ƶ�Я��֮�òŸտ�shi
OpenAI��HealthBench����һ�澵���������ӳ�ճ�ҽ��AI����״��δ���������������������AI��ҽ��������ش�DZ���������Ҳ������������ǰ�С�����̨���ҽ�ƻ��������ߡ��������������ѧ����������Լan�ҵ��yuan����������HealthBench��ֻ�����չ���������������ƶ�ҽ�ƴ���������������������Ҫͬ���������δ����������һ��������������������ҽ��AI����˸֮·�������